
My greatest interest in AI centers around language. I have used keywords to feign for language understanding and branching narrative to continue with character development and story. Both methods are effective at giving the appearance of seamless conversation or narrative, but neither could learn. I have done only a little bit of research on markov chains, but they fit into the original category of feigning understanding rather than true deep learning AI.

I wanted to learn in this class how close we are to computers really understanding and learning language without me hard-coding it. How much do Siri and Alexa rely on branching narrative and how much do they really “think for themselves” and get to know you? For the good of the world possibly, but the weakness of my potential projects, machine learning is certainly not where I imagined it might be. BUT I can say I now understand why it runs on vectors, matrices and differential equations.
As I started the process of testing neural networks, I first looked at the algorithm Char RNN, but since the machine learns on characters instead of full words, I felt like the amount of data the system would need to train on might be exponentially more than I wanted to attempt on my macbook air. I also remembered a post I had stumbled upon on Medium that trained the computer to sound like Harry Potter. That might be a better place to start.
Max Deutsch, a product manager at Intuit, wrote some great posts on the subject so I started with his tutorial to use a different algorithm, Word RNN. The code is written by Sung Kim and gives Shakespeare as its input text. The algorithm uses Google’s tensorflow and runs through the command line on the Mac. However for some reason on my computer, there were complications. The algorithm did not run as it was supposed to so I was forced to create a virtual system through my command line to train it.
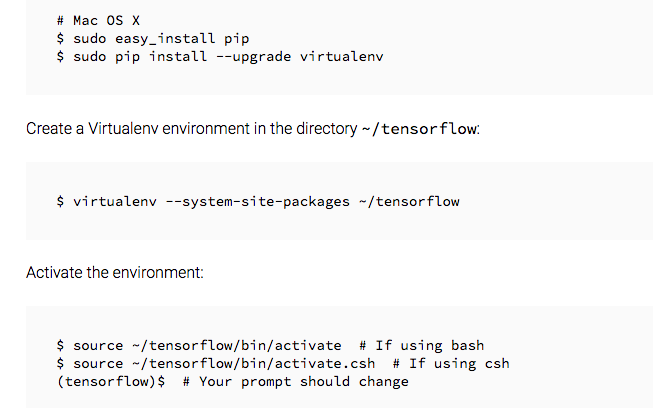
The good news is the tech trouble-shooting page for tensorflow is quite good as seen above. I was able to build this work around. Then 6-7 hours later, my computer spit out Shakespeare. Or did it?

I ran the training all day on Thanksgiving. At first my family was really impressed until they read the output. My macbook air was certainly not indecipherable from Shakespeare! But it did run. I realized the output worked better when the word number was more like a sentence or two. This limited my ideas a bit further for my project ideas, but led me to The Comeback.
What if I could train the neural network to give a comeback to every insult? Patrick Hebron and I discussed how to train a network on this and it might be possible. But it would need data structured with two characters to separate the lines. Let’s say a “$” and a “#”. After each insult, I could put in a dollar sign and after each comeback, a hashtag symbol. That would potentially work to train the network. I loved this idea, but the problem was finding enough data to train it. I would need thousands upon thousands of set ups and pay offs. Maybe over a long period of time, I could slowly collect the amount of data needed, but I could never accomplish it before the end of the semester so sadly this version of the project had to be set aside.

And I was already thinking of training the network on Armando Iannucci’s brilliant dialogue in Veep. That show has some of the best banter I’ve seen. Part of my curiosity with language and machine learning is testing if it could really pick up the rhythm and style of witty banter. Thanks to a curious British website, www.springfieldspringfield.uk.com, I found all of the teleplays. However, they were each typed by a viewer watching the shows on TV. There were endless typos and the punctuation and formatting were all over the place. I was not sure if it would train well, but I felt it was worth a shot so I trained Word RNN on the data. And seven hours later…
To see it a little better:
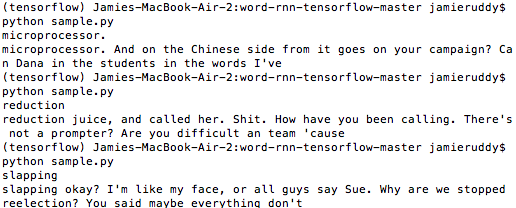
As you can see it worked again… sort of. I limited the word count to around 20 words on the first training. The sentences don’t all make sense, but after the response to Shakespeare, I did not have extremely high hopes. I also began to take apart the algorithm more. The output is all built around a single word picked randomly from the data. It would help if I could tell it what word to use. What if I traded all of the character names for Trump’s transition team? And what if I used the character names to prompt the output? That’s when I decided on Conversations from the Transition Bathroom. It could be funny snips of gossip the user overhears from a bathroom stall.

In order to get this to work, I would have to trade all the names in the 650 pages of teleplays. And since these are literally typed off the screen, some episodes had no capital letters. Others next to no punctuation and all had tons and tons of typos. The above was one of the best typed episodes, but still all of the hyphens had to be eliminated. I knew it would be time consuming, but nothing prepared me for the hours and hours it took over the course of numerous days. I first traded out the character names for different well known names connected to Trump. Then I tried to clean up the format, typos and spelling because I feared that might be another reason the training was weaker. Finally I reached a point where enough was enough and gave up another seven hours to train it one last time.
To test it with the specific names, I hard coded them into the sample.py script. I tried out everything from Veep favorites like “fuck” to random political words to names.
![]()
![]()
Every time I changed the word in these two spots, it would print out an output centered around that word. I also found it printed the name first on its own line before it did the output. I just needed to cut a line from the the model.py code to eliminate the first time it prints. Even though the sentences are not nearly what I wanted them to be, it was most interesting centered around specific names. But how do you let the user choose the name? I would need the Flask front end for that.
Patrick had showed me how to build a drop down menu in HTML to use for the names. Here’s the roughest version of it.
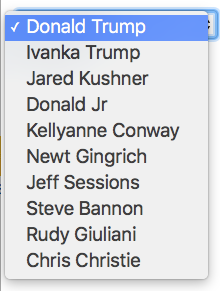
Once you put in a famous name from Trump and his notorious transition team, it was a lot more amusing. I spent a lot of hours combing through the data replacing it with these names so I needed to see the pay off!
BUT like the problem with tensor flow, there is something on my computer that also struggled with the Flask module. Although I followed the tutorial exactly, it did not work. With Patrick’s help and a virtual work around, I once more did get it to work. However, refreshing the Chrome local host page was not enough. After every single change to the HTML and Flask programming, I had to go into the command line and run the work around. This led to an extraordinarily time consuming process!

Then I would need to CD the flask folder and then run the python script. Since I’m no html expert, this is most definitely not the best way for me to work to build the front end! For now I can show a few snippets I ran directly in the command line.

Since the way the algorithm works, you can only put in a certain number of words and that might or might not complete a sentence, I decided to put an ellipsis at the end of each output. To add to this, I also chose to call them “overheard snippets” so complete thoughts would not be expected. Hopefully I will eventually get the front end completed, but at this point I only have the back end and the scaffolding to the user interface. I learned a ton about machine learning in this process so far, but I’m a lot more skeptical about computers stealing writing jobs any time soon.